
자바에서 데이터는 스트림을 통해 입출력되므로 스트림의 특징을 잘 이해해야 한다. 스트림은 단방향이라는 특성이 있어 입력과 출력용 두 가지 스트림이 존재한다.
자바의 기본적인 IO API는 java.io 패키지에서 제공하고 있다.
| java.io 패키지의 주요 클래스 | 설명 |
| File | 파일 시스템의 파일 정보를 얻기 위한 클래스 |
| Console | 콘솔로부터 문자를 입출력하기 위한 클래스 |
| InputStream / OutputStream | 바이트 단위 입출력을 위한 최상위 입출력 스트림 클래스 |
| FileInputStream / ...OutputStream | 바이트 단위 입출력을 위한 하위 스트림 클래스 |
| DataInputStream / ...OutputStream | |
| ObjectInputStream / ...OutputStream | |
| PrintStream | |
| BufferedInputStream / ...OutputStream | |
| Reader / Writer | 문자 단위 입출력을 위한 최상위 입출력 스트림 클래스 |
| FileReader / FileWriter | 문자 단위 입출력을 위한 하위 스트림 클래스 |
| InputStreamReader / OutputStreamWriter | |
| PrintWriter | |
| BufferedReader / BufferedWriter |
스트림 클래스는 바이트 기반 스트림, 문자 기반 스트림으로 구분된다. 바이트 기반 스트림은 그림, 멀티미디어, 문자 등 모든 종류의 데이터를 받고 보낼 수 있으나, 문자 기반 스트림은 오로지 문자만 받고 보낼 수 있도록 특화되어 있다.
바이트 기반 스트림의 하위 클래스들은 접미사로 InputStream 또는 OutputStream이 붙는다. 반면에 문자 기반 스트림의 하위 클래스들은 접미사로 Reader 또는 Writer가 붙는다.
공통 주의사항
OutputStream이나 Writer 모두 내부에 작은 버퍼가 있다. 따라서 더 이상 출력할 데이터가 없다면 버퍼에 잔류하고 있는 데이터를 비워주기 위하여 flush() 메서드를 호출하고 close() 메서드를 호출해서 스트림이 사용하고 있던 시스템 자원을 풀어줘야 한다. close() 메서드는 입력 스트림에서도 동일하게 수행해주어야 한다.
보조 스트림
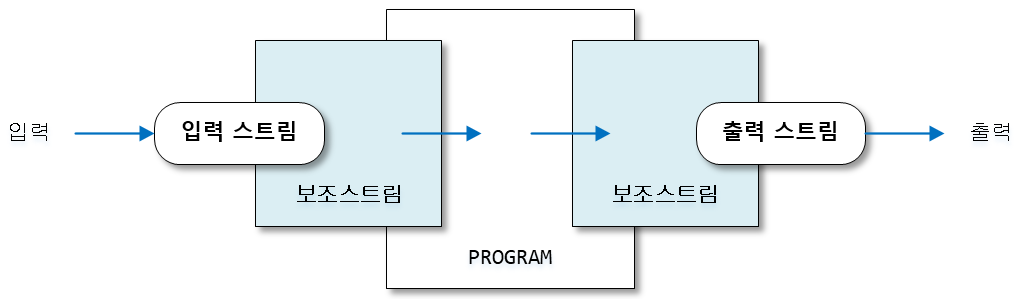
보조 스트림이란 다른 스트림과 연결되어 여러 가지 편리한 기능을 제공해주는 스트림을 말한다. 보조 스트림은 자체적으로 입출력을 수행할 수 없기 때문에 입력 소스와 바로 연결되는 스트림에 연결해서 입출력을 보조한다. 보조 스트림은 다음과 같은 보조 기능을 제공한다.
- 문자 변환
- 입출력 성능 향상
- 기본 데이터 타입 입출력
- 객체 입출력
문자 변환 보조 스트림
소스 스트림이 바이트 기반 스트림이면서 입출력 데이터가 문자라면 Reader와 Writer로 변환해서 사용하는 것을 고려해야 한다. Reader와 Writer는 문자 단위로 입출력이 가능하고 문자셋의 종류를 지정할 수 있기 때문에 다양한 문자를 입출력할 수 있다.
1. InputStreamReader
입력 스트림이 바이트 기반 스트림인 경우 InputStreamReader를 사용하면 입력 스트림을 Reader로 변환할 수 있다.
Reader reader = new InputStreamReader(바이트 기반 입력 스트림);FileInputStream의 경우 InputStreamReader를 연결하지 않고 FileReader를 생성할 수도 있다. 사실 FileReader는 InputStreamReader의 하위 클래스이고, 이는 FileReader가 결국 내부적으로 FileInputStream에 InputStreamReader를 연결한 것이라고 볼 수 있다.
1-1. 콘솔에서 한글 입력받고 출력하기
public class SubStream {
public static void main(String[] args) throws IOException {
InputStream is = System.in;
Reader reader = new InputStreamReader(is);
char[] cbuf = new char[100];
int readCharNo = reader.read(cbuf);
System.out.printf("readCharNo: %d\n", readCharNo);
System.out.printf("readData: %s", String.valueOf(cbuf, 0, readCharNo));
reader.close();
}
}System.in은 바이트 기반 최상위 입력 스트림인 InputStream을 제공한다. 해당 스트림을 InputStreamReader로 감싸서 문자 기반 입력 스트림인 Reader로 변환한 것이고 char buffer를 이용해서 2바이트 씩이 아닌 버퍼 크기만큼 읽어 들일 수 있도록 했다.
버퍼를 제공하지 않으면 2바이트(char size)씩 읽어들인다. 대량의 데이터를 읽어 들일 땐 비효율적이다
이후 버퍼의 데이터를 문자열로 변환하는데 String.valueOf()을 사용했다. Buffer와 offset, count를 제공하면 해당 크기만큼의 데이터를 String 객체로 변환해서 반환한다. offset, count를 제공하지 않으면 Buffer 크기만큼 변환 작업이 수행되므로 빈 공간에는 쓰레기 값이 들어갈 수 있다.
reader.close()의 내부 동작을 살펴보기 전에 내부 구조를 살펴보자.
- 사실 Reader는 추상 클래스이며 close() 메소드 또한 추상 메서드이다.
- Reader에 주입한 InputStreamReader는 Reader를 상속하는 자식 클래스이다.
- InputStreamReader를 생성할 때 사용한 생성자를 살펴보자.
/**
* Creates an InputStreamReader that uses the default charset.
*
* @param in An InputStream
*/
public InputStreamReader(InputStream in) {
super(in);
try {
sd = StreamDecoder.forInputStreamReader(in, this, (String)null); // ## check lock object
} catch (UnsupportedEncodingException e) {
// The default encoding should always be available
throw new Error(e);
}
}- 내부에서 StreamDecoder.forInputStreamReader를 호출하면서 StreamDecoder(== sd)라는 객체를 생성하는 것을 알 수 있다.
- StreamDecoder 또한 Reader를 상속하는 자식 클래스이다. StreamDecoder.forInputStreamReader를 살펴보자.
public static StreamDecoder forInputStreamReader(InputStream in,
Object lock,
String charsetName)
throws UnsupportedEncodingException
{
String csn = charsetName;
if (csn == null)
csn = Charset.defaultCharset().name();
try {
if (Charset.isSupported(csn))
return new StreamDecoder(in, lock, Charset.forName(csn));
} catch (IllegalCharsetNameException x) { }
throw new UnsupportedEncodingException (csn);
}- charset이 null이거나 지원하는 charset인 경우 StreamDecoder 생성자를 호출한다. 이때 전해진 InputStream은 StreamDecoder 내부에 in이라는 멤버 변수에 할당된다.
이제 reader.close()의 동작 과정을 살펴보자. Reader의 close()는 추상 메서드이므로 InputStreamReader가 구현한 close() 메서드를 살펴보자.
InputStreamReader class..
public void close() throws IOException {
sd.close();
}- sd.close()
- StreamDecoder의 close() 메서드 호출
StreamDecoder class...
public void close() throws IOException {
synchronized (lock) {
if (closed)
return;
implClose();
closed = true;
}
}- boolean closed 변수의 값으로 stream이 closed 상태인지 확인한다. 이때 synchronized (lock)을 통해서 closed 변수 접근에 대한 스레드 간 동기화 이슈를 해결하는 것을 볼 수 있다. lock 변수에 대해서 살펴보자.
Reader class...
/**
* The object used to synchronize operations on this stream. For
* efficiency, a character-stream object may use an object other than
* itself to protect critical sections. A subclass should therefore use
* the object in this field rather than {@code this} or a synchronized
* method.
*/
protected Object lock;
/**
* Creates a new character-stream reader whose critical sections will
* synchronize on the reader itself.
*/
protected Reader() {
this.lock = this;
}- Reader의 기본 생성자는 lock 멤버 변수에 자기 자신을 할당하고 있다. 즉 StreamDecoder의 close() 메서드에는 하나 이상의 스레드가 접근할 수 없으며 동기화를 보장하는 것이다.
- lock을 얻고 만약 closed == false 라면 implClose()를 호출한다.
StreamDecoder class...
void implClose() throws IOException {
if (ch != null)
ch.close();
else
in.close();
}- 여기서 ch는 ReadableByteChannel을 가리킨다. ReadableByteChannel은 Channel 개념과 연관되어 있는데 지금은 Stream을 다루기 때문에 일단 넘어가도록 하자. 여기서 추측해 볼 만한 점은 Channel과 InputStream을 동시에 사용할 일은 없어 보인다는 것이다. 왜냐하면 Channel이 존재하면 Channel만 close 하고 함수를 종료하기 때문이다.
- Channel은 Java NIO에서 쓰이는 개념이므로 추후 NIO를 살펴보면서 다시 살펴볼 것이다.
2. OutputStreamReader
2-1. 콘솔로 출력하기
public class OutputStreamReaderTest {
public static void main(String[] args) throws IOException {
OutputStream os = System.out;
Writer writer = new OutputStreamWriter(os);
String data = "안녕하세요";
writer.write(data);
writer.flush();
writer.close();
}
}- System.out은 OutputStream의 하위 클래스인 PrintStream을 반환한다. PrintStream은 스트림을 화면에 출력할 때 사용하며 FilterOutputStream을 상속받는 자식 클래스이다.
- writer.write() 이후에 flush()를 진행하는 이유는 버퍼에 남아 있는 데이터를 출력하기 위함이다.
성능 향상 보조 스트림
프로그램의 실행 성능은 입출력이 가장 늦은 장치를 따라간다. 이때 입출력과 프로그램의 속도 차이를 해소하기 위하여 중간에 메모리 버퍼를 사용함으로써 실행 성능을 향상시킬 수 있다. 버퍼는 데이터가 쌓이기를 기다렸다가 꽉 차게 되면 데이터를 한꺼번에 하드 디스크로 보냄으로써 출력 횟수를 줄여준다.
보조 스트림 중에서는 위와 같이 메모리 버퍼를 제공하여 프로그램의 입출력 성능을 향상시키는 것들이 있다. 바이트 기반 스트림에는 BufferedInputStream/OutputStream이 있고 문자 기반 스트림에는 BufferedReader/Writer가 있다.
1. BufferedOutputStream과 BufferedWriter
BufferedOutputStream은 바이트 출력 스트림에 연결되어 버퍼를 제공해주는 보조 스트림이고, BufferedWriter는 문자 출력 스트림에 연결되어 버퍼를 제공해주는 보조 스트림이다. BufferedOutputStream은 8192 바이트, BufferedWriter는 8192 문자를 최대로 저장할 수 있다. 버퍼 사이즈는 생성자 매개변수로 지정할 수 있다.
BufferedOutputStream bos = new BufferedOutputStream(바이트 기반 출력 스트림);
BufferedWriter bw = new BufferedWriter(문자 기반 출력 스트림);주의할 점은 버퍼가 가득 찼을 때만 출력하기 때문에 버퍼가 가득차지 않을 경우 버퍼에 데이터가 잔류할 수 있다. 따라서 flush() 메서드로 남은 데이터가 없도록 해야 한다. 파일 복사 예제를 통해서 성능이 얼마나 향상되는지 확인해보자.
package SubStream;
import java.io.*;
public class BufferedOutputStreamTest {
public static void main(String[] args) throws Exception {
int data = -1;
long start;
long end;
String path = BufferedOutputStreamTest.class.getResource("").getPath();
try(
FileInputStream fis = new FileInputStream(path + "image.png");
BufferedInputStream bis = new BufferedInputStream(fis);
FileOutputStream fos = new FileOutputStream(path + "./test.png");
) {
start = System.currentTimeMillis();
while((data = bis.read()) != -1) { // 이곳에서 병목현상 발생
fos.write(data);
}
fos.flush();
end = System.currentTimeMillis();
System.out.printf("사용하지 않았을 때: %dms\n", (end - start));
} catch(Exception e) {
System.out.println(e.getMessage());
}
try(
FileInputStream fis = new FileInputStream(path + "./image.png");
BufferedInputStream bis = new BufferedInputStream(fis);
FileOutputStream fos = new FileOutputStream(path + "./test.png");
BufferedOutputStream bos = new BufferedOutputStream(fos);
) {
start = System.currentTimeMillis();
while((data = bis.read()) != -1) { // 버퍼로 병목현상 해소
bos.write(data);
}
bos.flush();
end = System.currentTimeMillis();
System.out.printf("사용했을 때: %dms\n", (end - start));
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}
// ================ log ==================================================================
사용하지 않았을 때: 391ms
사용했을 때: 13ms기본 타입 입출력 보조 스트림
바이트 스트림은 바이트 단위로 입출력하기 때문에 자바의 원시 데이터 타입 단위로 입출력할 수 없다. 그러나 DataInputStream과 DataOutputStream 보조 스트림을 연결하면 원시 데이터 타입과 String 입출력이 가능하다. 생성자는 다른 보조 스트림들과 동일하게 바이트 기반 입출력 스트림을 매개값으로 넣어주면 된다.
DataInputStream dis = new DataInputStream(바이트 기반 입력 스트림);
DataOutputStream dos = new DataOutputStream(바이트 기반 출력 스트림);이 보조 스트림으로 데이터를 입출력할 때 주의할 점은 데이터를 출력한 순서대로 데이터를 읽어야 한다.
public class DataOutputStreamTest {
public static void main(String[] args) {
try {
String path = DataOutputStreamTest.class.getResource("").getPath();
FileOutputStream fos = new FileOutputStream(path + "data.dat");
DataOutputStream dos = new DataOutputStream(fos);
dos.writeUTF("뇌장하드");
dos.writeDouble(80.5);
dos.writeInt(10);
dos.flush();
dos.close();
fos.close();
FileInputStream fis = new FileInputStream(path + "data.dat");
DataInputStream dis = new DataInputStream(fis);
String name = dis.readUTF();
double score = dis.readDouble();
int order = dis.readInt();
dis.close();
fis.close();
System.out.printf("%s 점수[%.2f], 등수[%d]", name, score, order);
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}객체 입출력 보조 스트림
자바는 객체를 파일 또는 네트워크로 출력해야할 때가 있다. 사용자의 데이터를 파일로 백업할 수도 있을 것이고 다른 프로그램에 공유해야 할 수도 있을 것이다. 이를 위해서는 객체를 바이트로 변경해야 하는데, 이것을 객체 직렬화(Serialization)라고 한다. 반대로 바이트 형태의 데이터를 객체로 복원하는 것은 역직렬화(deserialization)라고 한다.
1. ObjectInputStream과 ObjectOutputStream
둘 다 바이트 입출력 스트림에 의존하는 보조 스트림이며 생성자에 매개값으로 의존하는 스트림을 전달하면 된다.
ObjectInputStream ois = new ObjectInputStream(바이트 기반 입력 스트림);
ObjectOutputStream oos = new ObjectOutputStream(바이트 기반 출력 스트림);public class ObjectInputOutputStreamTest {
public static void main(String[] args) {
try {
String path = ObjectInputOutputStreamTest.class.getResource("").getPath();
FileOutputStream fos = new FileOutputStream(path + "object.dat");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(new Integer(10));
oos.writeObject(new Double(3.14));
oos.writeObject(new int[] {1, 2, 3});
oos.writeObject(new String("뇌장하드"));
oos.flush();
oos.close();
fos.close();
FileInputStream fis = new FileInputStream(path + "object.dat");
ObjectInputStream ois = new ObjectInputStream(fis);
Integer obj1 = (Integer) ois.readObject();
Double obj2 = (Double) ois.readObject();
int[] obj3 = (int[]) ois.readObject();
String obj4 = (String) ois.readObject();
ois.close();
fis.close();
System.out.println(obj1);
System.out.println(obj2);
System.out.printf("[%d, %d, %d]\n", obj3[0], obj3[1], obj3[2]);
System.out.println(obj4);
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}참조 타입 생성자를 사용하고 있는데 그냥 값만 절달해도 Auto Boxing이 적용되기 때문에 상관없다.
Auto Boxing 또는 Unboxing은 단일 건에 대해서는 큰 성능 저하가 없겠지만 반복문을 이용한 연산 작업에서 연속적으로 Auto Boxing이나 Unboxing이 이루어지면 성능 저하가 발생할 수 있다. 따라서 반복적인 연산 작업에서는 동일한 타입으로 연산을 수행하는 것이 좋다.
2. 직렬화가 가능한 클래스(Serializable)
자바는 Serializable 인터페이스를 구현한 클래스만 직렬화할 수 있도록 제한하고 있다. Serializable 인터페이스는 필드나 메서드가 없는 빈 인터페이스이지만, 객체를 직렬화할 때 private 필드를 포함한 모든 필드를 바이트로 변환해도 좋다는 표시 역할을 한다.
객체를 직렬화하면 바이트로 변환되는 것은 필드들이고, 생성자 및 메서드는 직렬화에 포함되지 않는다. 따라서 역직렬화할 때에는 필드의 값만 복원된다. 하지만 필드 선언에 static 또는 transient가 붙어 있을 경우에는 직렬화가 되지 않는다.
transient 키워드는 특정 필드를 직렬화 대상에서 제외시키고 싶을 때 사용하는 키워드이다. transient가 적용되면 필드가 아예 직렬화 대상에서 배제되기 때문에 역직렬화를 수행하면 null 값이 들어가게 된다. 따라서 직렬화 역직렬화 시 transient 키워드 사용에 대한 충분한 합의가 있어야 한다.
class TestClass implements Serializable {
private final int age;
private final String name;
private final transient String uuid;
TestClass(int age, String name) {
this.age = age;
this.name = name;
this.uuid = UUID.randomUUID().toString();
}
@Override
public String toString() {
return "TestClass [" + this.age + ", " + this.name + ", " + this.uuid + "]";
}
}
public class ObjectInputOutputStreamTest {
public static void main(String[] args) {
try {
String path = ObjectInputOutputStreamTest.class.getResource("").getPath();
FileOutputStream fos = new FileOutputStream(path + "class.dat");
ObjectOutputStream oos = new ObjectOutputStream(fos);
TestClass testClass = new TestClass(10, "name");
System.out.println("직렬화 전");
System.out.println(testClass);
System.out.flush();
oos.writeObject(testClass);
oos.flush();
oos.close();
fos.close();
FileInputStream fis = new FileInputStream(path + "class.dat");
ObjectInputStream ois = new ObjectInputStream(fis);
TestClass res = (TestClass) ois.readObject();
System.out.println("역직렬화 후");
System.out.println(res);
ois.close();
fis.close();
} catch (Exception e) {
System.out.println(e);
}
}
}
// ===== log ===========================================================================
직렬화 전
TestClass [10, name, 39a3f702-e795-4a90-a23e-7a6a33864f26]
역직렬화 후
TestClass [10, name, null]위 코드에서는 직렬화 역직렬화 과정을 살펴볼 수 있고 transient 키워드 사용 결과를 볼 수 있다.
3. serialVersionUID
직렬화된 객체를 역직렬화할 때는 동일한 클래스를 사용해야 한다. 만약 한쪽에서 클래스의 내용이 변경되어 재컴파일되는 경우 serialVersionUID 값이 변경되어 역직렬화에 실패하게 된다. 만약 어느 쪽에서든 클래스가 수정될 수 있는 상황이라면 serialVersionUID를 명시적으로 선언하여 관리하는 것이 좋다.
public class XXX implements Serializable {
static final long serialVersionUID = 정수값;
...
}serialVersionUID는 가능하다면 클래스마다 다른 값을 갖도록 하는 것이 좋다. 자바에서는 serialver.exe 명령어를 제공하는데 이를 이용하면 중복되지 않는 serialVersionUID를 얻을 수 있다.
4. writeObject()와 readObject() 구현
두 클래스가 상속 관계에 있을 때 부모 클래스가 serializable 인터페이스를 구현하고 있으면 자식 클래스는 serializable 인터페이스를 구현하지 않아도 자식 객체를 직렬화하면 부모 필드 및 자식 필드가 모두 직렬화된다. 하지만 반대로 자식 클래스만 serializable 인터페이스를 구현하고 있으면 자식 객체를 직렬화할 때 부모의 필드는 직렬화에서 제외된다. 만약 부모 필드도 직렬화하고 싶다면 두 가지 선택지가 있다.
- 부모 클래스도 serializable 인터페이스를 구현한다.
- 자식 클래스에서 writeObject()와 readObject()를 구현한다.
첫 번째 방법이 가장 깔끔하지만, 부모 클래스를 수정할 수 없는 경우에는 자식 클래스에서 두 메서드를 직접 구현하면 된다. 구현할 때 주의할 점은 접근 제한자가 private이 아니면 자동 호출되지 않는다는 점이다.
private void writeObject(ObjectOutputStream out) throws IOException {
out.writeXXX(부모 필드);
...
out.defaultWriteObject(); // 자식 객체의 필드값을 직렬화
}위 코드처럼 구현하면 되고 readObject 메서드도 구현하는 방식은 동일하다.
'JAVA' 카테고리의 다른 글
| [기본 시리즈] JAVA 스레드에 대하여 (0) | 2022.09.08 |
|---|---|
| [기본 시리즈] java.io 자바 기본 네트워킹 TCP/IP (0) | 2022.09.06 |
| [기본 시리즈] JVM의 메모리 사용 구조 : Thread 영역 (0) | 2022.08.23 |
| [기본 시리즈] 해시 테이블과 해시 충돌 그리고 JAVA의 HashMap (0) | 2022.08.18 |
| [기본 시리즈] JAVA 특징 및 JVM에 대하여 (0) | 2022.08.17 |