
컬렉션 프레임워크 끝내기 #List
List 컬렉션은 다음과 같은 계층 구조를 가지고 있다. List 컬렉션에는 ArrayList, LinkedList, Vector와 같은 구현 클래스들이 있다.

LinkedList의 경우 다중 인터페이스 구현 클래스이다. List 인터페이스와 Deque 인터페이스를 둘 다 구현하고 있음을 알 수 있다.
ArrayList
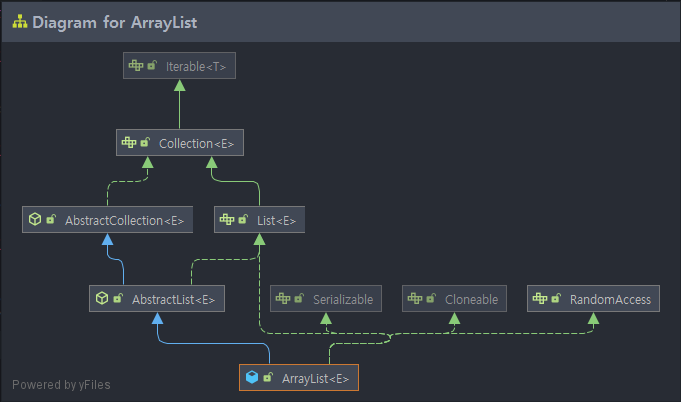
대표적인 List 구현 클래스이다. 일반 배열과 ArrayList는 인덱스로 객체를 관리한다는 점이 유사하지만, 배열은 고정형 메모리를 가지고 ArrayList는 동적 메모리 구조를 가진다는 점이 다르다. 즉 ArrayList는 size를 조절할 수 있다. 초기에 사이즈를 지정하는 방법은 다음과 같다.
List<String> list = new ArrayList<String>(30);
// 또는
List<String> list = new ArrayList<>(30);<String> 과 <> 둘 중 어느 방식으로 사용해도 무관하다. 이는 거의 모든 컬렉션 프레임워크에서 동일한데, 그 이유는 거의 모든 구현 클래스가 Generic 클래스이기 때문이다. (<>) 이 꺽쇠를 다이아몬드라고 하는데, 이것을 사용하면 자바 컴파일러는 코드 문맥으로부터 타입을 추론할 수 있다.
그러나 ArrayList도 결국 내부적으로 Array를 사용하기 때문에 연속된 메모리 구조를 가진다. 연속된 메모리 구조는 삽입 또는 삭제에서 굉장히 비효율적이다. 만약 2번 인덱스의 객체를 제거하면 ArrayList는 2번 이후의 객체들을 모두 한 칸씩 당겨와야 하고 삽입한다면 뒤로 모두 밀어내야 하며 O(n)의 Time Complexity를 가진다. 따라서 객체의 삽입 삭제가 빈번한 로직에서는 ArrayList를 권장하지 않는다. 그러나 ArrayList는 기본적인 배열답게 인덱스를 이용한 접근과 맨 뒤에서의 삽입, 삭제에 상수 시간 복잡도를 가진다.
추가적으로 Java의 ArrayList는 add()와 addAll()을 수행할 때 어떤 식으로 메모리를 동적 할당하는지 확인해보자. 먼저 add()는 추가 메모리 할당을 위해 내부에서 grow() 함수를 호출한다.
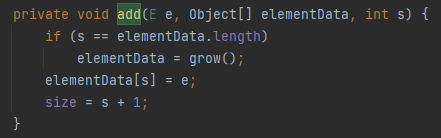
addAll()은 grow(minCapacity)를 호출한다. (오버로드된 다른 함수들도 마찬가지)
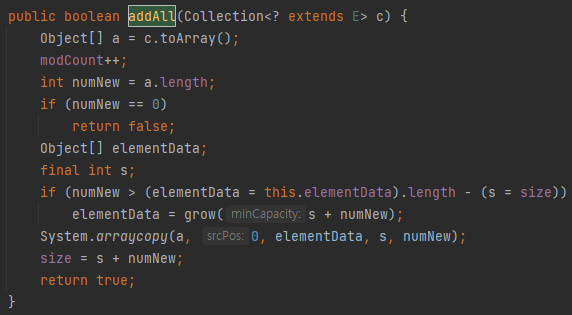
이제 grow() 함수를 살펴보면 아래와 같이 두 개의 grow() 함수가 오버로드 되어 있다. 두 번째 grow()는 보통 add()에서 호출하고 첫 번째 grow()는 보통 addAll()에서 호출한다. 그런데 두 번째 grow() 함수는 단순히 첫 번째 grow() 함수를 재호출하므로 첫 번째 grow() 함수만 살펴보면 된다.

첫 번째 grow() 함수는 내부에서 newCapacity()라는 함수를 호출한다. newCapacity() 함수는 만약 newCapacity(현재 배열 크기의 1.5배 크기)가 주어진 minCapacity보다 작거나 같은 경우에는 현재 배열이 빈 배열인지 혹은 minCapacity에서 오버플로우가 발생했는지 등을 확인한다. 반대로 newCapacity가 minCapacity보다 큰 경우에는 newCapacity가 MAX_ARRAY_SIZE 보다 작거나 같다면 newCapacity를 정상적으로 반환하고 그렇지 않은 경우 매우 큰 배열 사이즈라고 판단해서 hugeCapacity 함수를 호출한다. hugeCapacity 함수는 별 내용이 없다.

즉 add() 또는 addAll() 함수는 내부적으로 결국 newCapacity(minCapacity) 함수를 호출한다. 그런데 무조건 1.5 배 크기의 메모리 공간을 리턴하는 것이 아니고 동작 수행을 위한 최소한의 용량인 minCapacity와 1.5 배 용량인 newCapacity 중에서 더 적합한 용량을 선택하고 할당하는 것을 알 수 있다.
Vector
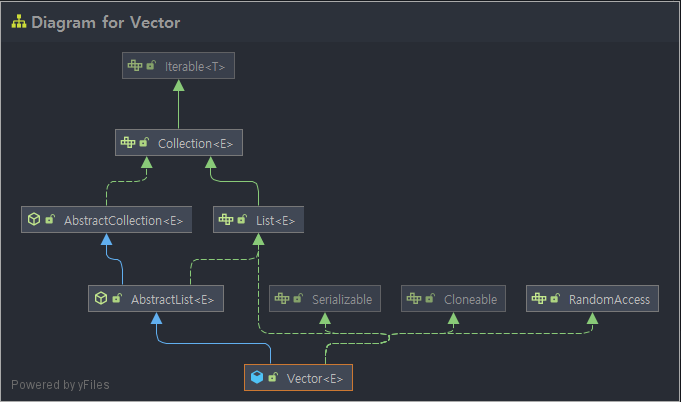
ArrayList와 동일한 구조를 가지고 있다. 하나 다른 점은, Vector는 동기화된(Synchronized) 메서드로 구성되어 있기 때문에 멀티 스레드가 동시에 접근할 수 없다. 즉 하나의 스레드가 실행을 완료해야만 다른 스레드를 실행할 수 있다. 따라서 멀티 스레드 환경에서 안전하여 Thread Safe 하다.
LinkedList (Double LinkedList)
List 구현 클래스이므로 ArrayList와 사용 방법은 똑같지만 내부 구현은 완전히 다르다. ArrayList는 내부 배열에서 객체를 인덱스로 관리하지만, LinkedList는 인접 참조를 통해서 내부 객체를 관리한다.

객체의 삽입 또는 삭제가 일어나는 경우 해당 위치를 가리키는 인접 참조 값만 수정해주면 되기 때문에 삽입, 삭제 연산에서 O(1)의 Time Complexity를 가진다. 즉 ArrayList가 삽입, 삭제 연산에 불리한 반면에 LinkedList는 매우 유용한 구조를 가지고 있다. 그러나 LinkedList도 단점이 있다. 인덱스를 사용하지 않기 때문에 객체를 찾기 위해서는 모든 객체를 확인해야 한다. 따라서 최악의 경우 검색에서 O(n)의 Time Complexity를 가진다.
Stack
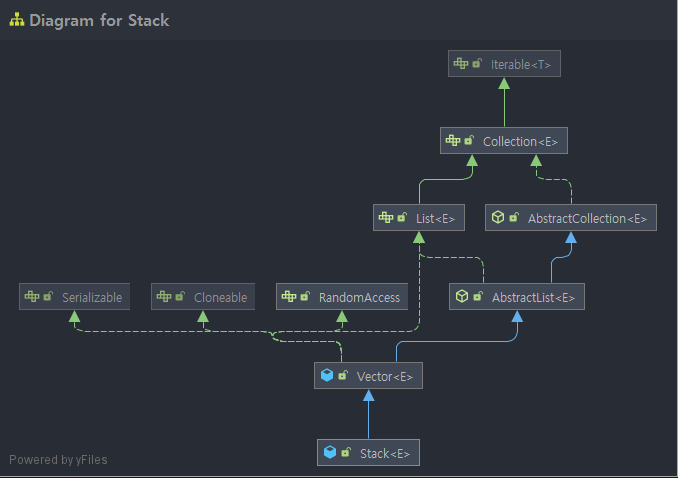
Stack 클래스는 단순히 Vector 클래스를 상속받은 자식 클래스이다. Stack 역할에 맞는 고유한 메서드가 추가적으로 구현되어 있을 뿐이다. (pop, push, peek 등...) 그런데 Vector를 상속하고 있고, 따로 추가된 메소드들도 Syncronized 키워드를 통해 동기화를 보장하고 있기 때문에 Stack 클래스 또한 Thread-safe다.
'JAVA' 카테고리의 다른 글
| [기본 시리즈] 해시 테이블과 해시 충돌 그리고 JAVA의 HashMap (0) | 2022.08.18 |
|---|---|
| [기본 시리즈] JAVA 특징 및 JVM에 대하여 (0) | 2022.08.17 |
| 어노테이션에 대하여 (0) | 2022.07.16 |
| JAVA 예외 처리 (0) | 2022.07.11 |
| 프로젝트 JAVA 컨벤션 (0) | 2022.05.08 |