
여러 기술블로그 글을 통해서 페이징을 할 때에는 OOM을 방지하기 위해 fetch join을 삼가해야 한다는 것을 알고 있었다. 왜냐하면 JPA가 distinct를 고려하여 페이징 조건을 맞추기 위해 모든 데이터를 메모리에 불러오기 때문이다. 이는 OOM을 발생시킬 수 있기 때문에 굉장히 위험하며 @OneToMany 또는 @ManyToMany 관계에서 해당되는 이야기이다.
왜 @OneToMany 또는 @ManyToMany에서만 해당되는 이야기일까? OneToMany를 예로 들자면 1의 입장에서 fetch join을 수행할 때 1에 해당하는 데이터가 N개 만큼 쪼개지는 현상이 발생한다. 말로 설명하기 어려운데 다음 그림을 참고하면 좋을 것 같다.

위 그림처럼 쿼리의 결과로 group1이 두 번 나타나는 현상을 방지하기 위하여 distinct 키워드를 이용하는 것이다. 따라서 distinct와 페이징 두 가지를 모두 고려하다 보니 JPA는 인메모리에 모든 데이터를 가져오고 distinct를 적용한 후에 페이징 조건에 맞게 결과값을 반환하는 것이다.
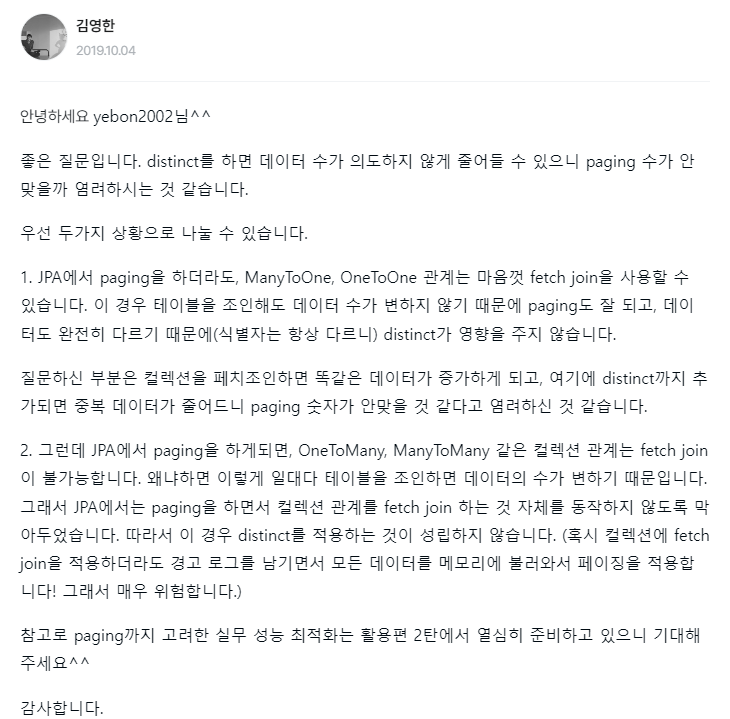
그럼 OneToOne의 경우는? OneToOne의 경우 쉽게 생각하면 위 그림에서 group1이 여러 User를 가질 일이 애초에 없다. 즉 distinct 키워드가 영향을 주지 않는다. 따라서 우리가 우려하던 문제는 발생하지 않는다. 아래는 영한님의 자세한 답변이다.
reference
'JPA' 카테고리의 다른 글
| OneToOne 정리 (0) | 2022.08.29 |
|---|---|
| JPA fetch join 대상의 별칭 사용과 주의사항 (0) | 2022.08.16 |
| JPA에서 발생할 수 있는 문제들과 해결방법 정리 (N + 1, 무작위 JOIN..) (0) | 2022.08.09 |
| JPA 동시성 문제 해결하기 (낙관적 락, 비관적 락) (0) | 2022.08.01 |
| JOIN vs Fetch JOIN with JPA (0) | 2022.06.24 |